从 DeepSeek-R1 看推理大模型:如何让 AI 学会"思考"?

从 2024 年以来,以 GPT、DeepSeek-R1、Qwen 等为代表的推理大模型,在解决复杂问题方面展现出突破性的进展。它们不仅提升了复杂任务的处理能力,还推动了 AI 在逻辑推理、数学计算、代码生成等领域的应用。本文将以 DeepSeek-R1 为例,从人类推理机制出发,探讨大语言模型如何学会“思考”。
一、理解“推理”
推理(Reasoning)有多种定义方式。本文中,我们将推理定义为:在处理复杂问题时的思考过程。
1. 人类是如何推理的?
当我们面对问题时,通常会经历两种情况:
- 简单问题:对某些问题,我们几乎可以脱口而出答案,例如“你贵姓?”。这类问题只需要依赖记忆,而无需思考;
- 复杂问题:需要经过思考才能得出答案。
面对复杂问题,我们通常会回忆相关知识,并在大脑中建立不同知识点之间的联系,以推导出最终结论。这个过程是实时进行的,而非预先存储在大脑中的固定答案。
在推理大模型诞生之前,大语言模型(LLM)往往将所有问题都视为简单问题,在看完问题后直接输出答案,其本质缺失了“中间思考”环节,如同人类未经思考直接作答。因此,它们在真正复杂问题上的表现并不理想。
2. 让 AI 学会推理的关键
要让大模型具备推理能力,首先需要给它思考的时间。在生成最终答案之前,鼓励它尽可能多地“思考”。
但与人类不同,LLM 不会在脑子里默默思考,它的所有推理过程都需要通过文本展现出来。换句话说,如果模型没有显式输出推理过程,那就等于没有思考过。
这带来了一个启发:
要求模型尽可能多地输出内容,以此迫使它进行推理。
在推理大模型出现之前,一种经典的促使 LLM 进行思考的方法是 思维链(Chain of Thought, CoT)。通过引导模型逐步推导答案,可以有效提升其解决复杂问题的能力。
此外,还有一个重要现象:Inference-time scaling。
即随着推理阶段(Inference)计算资源和时间的增加,模型的输出内容也随之增加,其准确率也会随之提升。这里的“inference”指的是模型的预测输出过程,而“reasoning”更强调推理的过程。
接下来,我们来看 DeepSeek-R1 是如何将“思考能力”植入模型的。
二、R1 是如何学会推理(Reasoning)的
目前,大模型的训练通常采用 预训练(Pre-Training)+ 后训练(Post-Training) 的方式。其中,预训练阶段主要让模型学习广泛的知识和语言能力,而后训练则进一步强化特定的技能,如推理、问题回答以及对人类价值观的适应能力。例如,DeepSeek-V3 和 ChatGPT 这样的模型,都是通过后训练阶段赋予它们了更自然的人机交互能力。
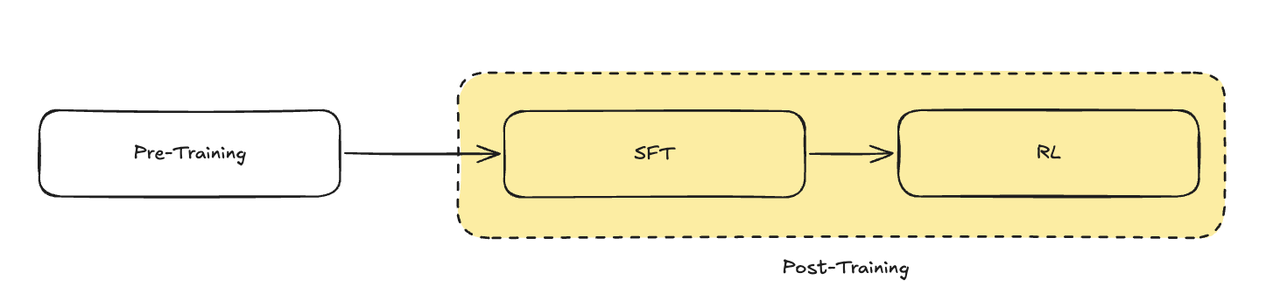
可以将预训练比作通识教育,旨在让模型掌握广泛的基础知识;而后训练则类似专业教育,使模型在特定领域表现得更精通。
然而,在增强某种专业能力(如推理)时,可能会导致模型在预训练阶段学到的基础能力有所衰退。因此,如何在提升推理能力的同时,尽量减少基础能力的损失,成为后训练阶段的一大挑战。
DeepSeek-R1 模型是从 DeepSeek-V3-Base 模型上开发而来的,V3-Base 本身只经历了预训练阶段,没有进行监督微调(Supervised Fine-Tune,SFT)和强化学习(Reinforce Learning,RL)。
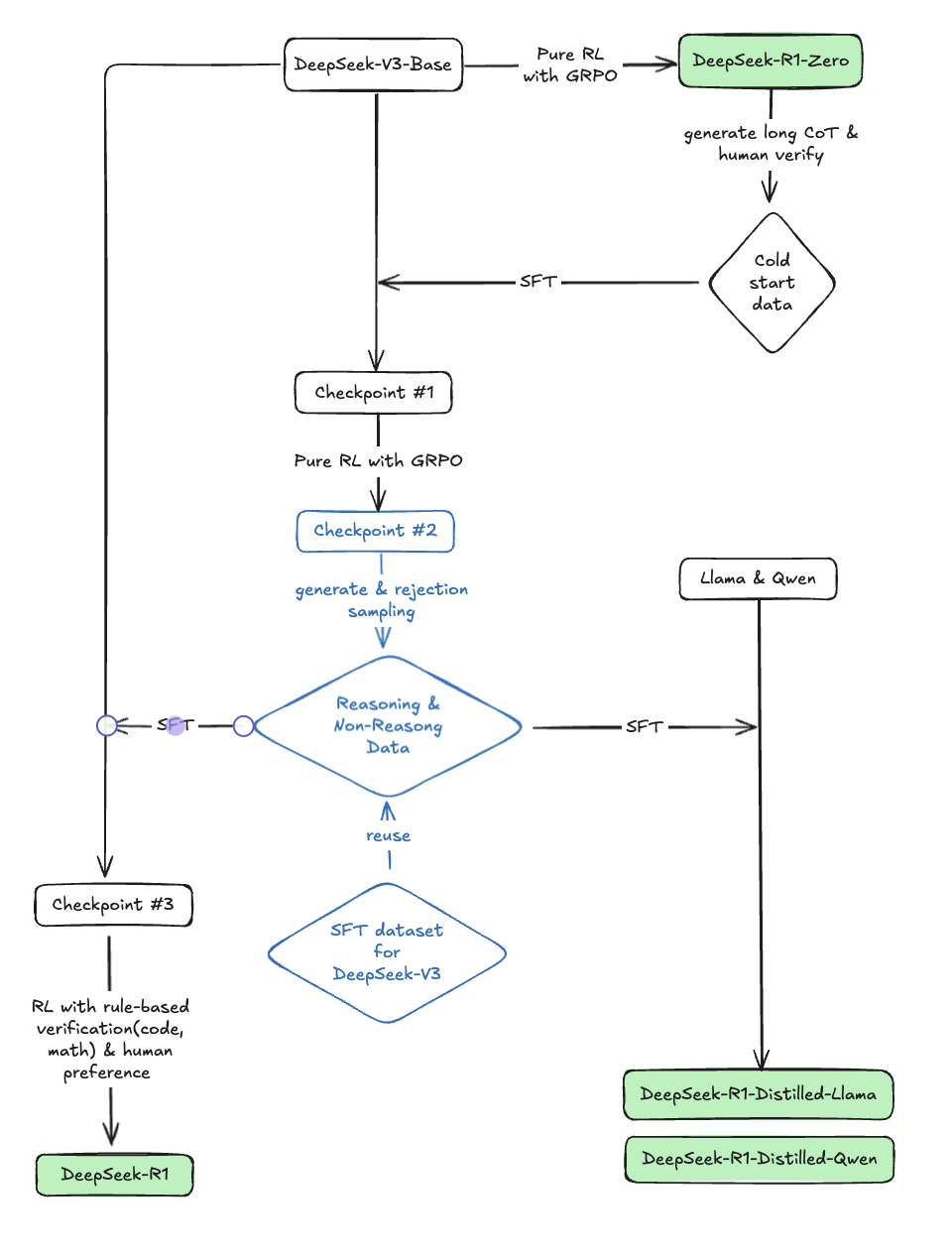
下图是我根据 R1 模型的技术报告梳理出的框架图,我将根据这个框架图,来逐个分析 R1 实现的各个模块。
1. DeepSeek-R1-Zero:跳过 SFT 的强化学习
首先来看 DeepSeek-R1-Zero 这个模型,如图所示,这是整个训练过程中的第一个重要输出。

这个模型的特别之处在于,它并没有经历 SFT 阶段,而是直接纯强化学习的方式来增强 DeepSeek-V3-Base 的推理能力。这一过程中,没有使用任何标注数据,所有模型参数的更新都是由无监督的强化学习来驱动的。
Deepseek 团队为这一阶段的强化学习设计了两种类型的奖励,其中并不包含神经奖励模型:
- 正确性奖励:通过基于规则的方式来验证模型输出的答案是否正确;
- 格式奖励:引导模型在输出的内容,满足
<think>思考过程</think><answer>答案</answer>这种格式,满足这种格式的输出,模型会得到更多的奖励。
针对第一种类型的奖励,我们很好理解,就是为了鼓励模型把问题回答对。那第二种类型的格式奖励,为什么要这么设计呢。我们可以类比一下之前说的人类面对复杂问题的处理过程,第一步是思考,第二步是回答。思考的过程往往都是在脑子里进行的,并不会说出来。如果 think 标签中的内容是思考的内容, answer 标签中的内容是回答的内容,我们就会惊奇的发现,通过这种简单的格式设计,我们就对齐了模型思考和人类思考的方式。
再啰嗦一点,这个强化学习的过程做了两件事情,第一鼓励模型按照固定的套路输出内容,这样在形式上,模型就有了思考和回答的两个阶段。第二,在满足上面输出范式的同时,尽可能的把问题回答对,如果要回答对问题,模型就需要更多的思考,也就是 think 标签中的内容会越来越多。
不过,模型训练的过程并不是按照上面介绍的先学习第一步再学习第二步,而是两个方面一起学习的,所以如何能稳定训练让模型能够收敛,是一件非常难的事情。DeepSeek 团队使用的 GRPO(Group Relative Policy Optimization) 算法,这是他们自己团队提出的一个算法,相较于之前的强化学习算法,该算法可以有效的减少计算资源、提供训练稳定性。
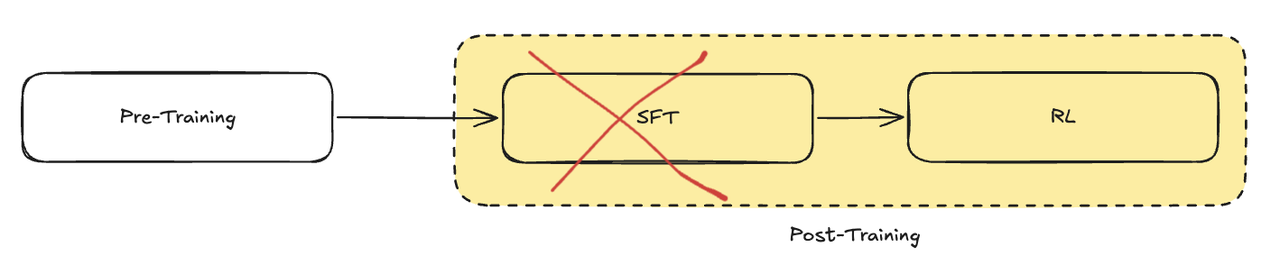
DeepSeek 是第一个提出只使用强化学习来增强模型推理能力的团队,打破了原有的后训练阶段先 SFT 后 RL 的方式,直接面向目标进行优化,以自主学习代替数据依赖,这也体现了第一性原理:哪怕是三岁的小孩,不告诉他任何道理,只是通过对其行为进行奖励和惩罚的方式,也可以使他取得进步,更何况是这么“聪明”的模型呢。
经过强化学习之后,R1-Zero 展现出了很强的自我反思和推理能力,但存在着很多缺点,比如输出的内容可读性不强,语言混杂(language mixing)等。
2. Cold Start:引入 SFT 训练
为了训练出一个更有用的推理模型,DeepSeek 选择回到传统的方式上,使用 Pretrain->SFT->RL 的方式来微调 DeepSeek-V3-Base 模型进行后训练,而不是使用 R1-Zero 那样跳过 SFT 阶段直接 RL 的方式。只不过,这个 SFT 阶段所使用的数据,是由 R1-Zero 经过精心设计的 prompt 所产生的 long CoT 的数据,再经过人工筛选、修正后用于微调模型。这部分数据 DeepSeek 团队称为冷启动数据(Cold-Start Data),数据规模为数千条。
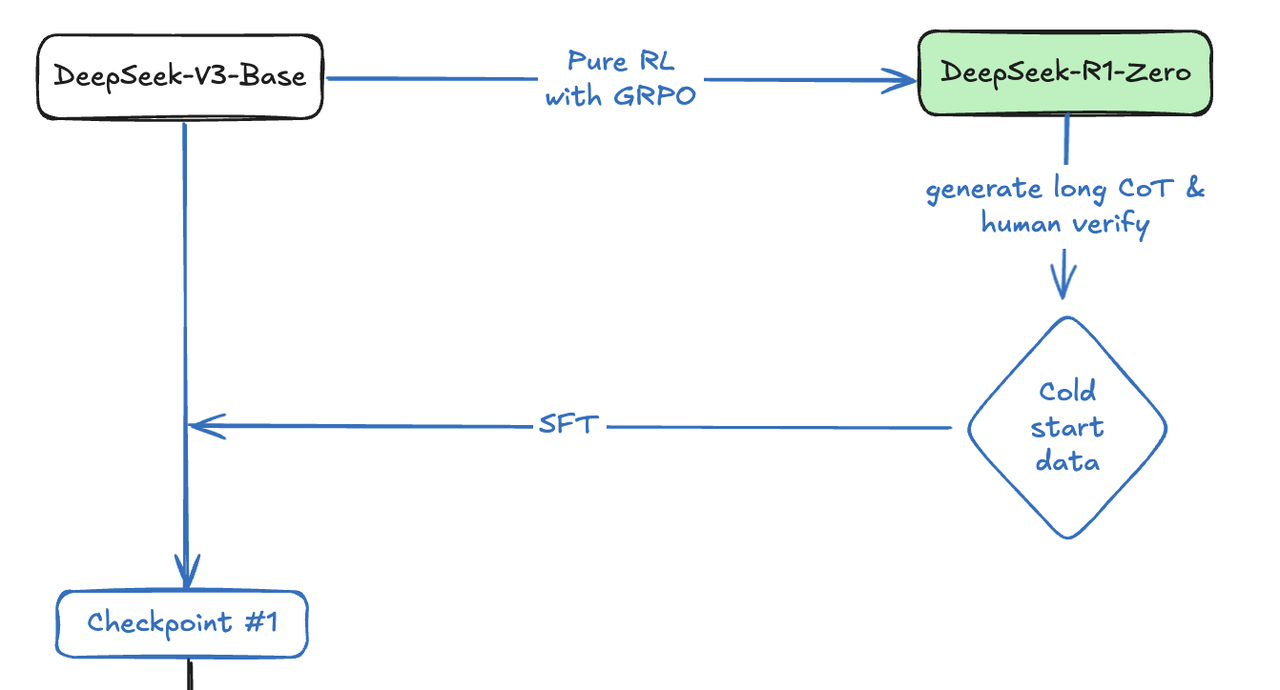
第一步:SFT with Cold-Start Data
从图中可以看出,有了冷启动的数据后,使用这部分数据对 DeepSeek-V3-Base 模型进行 SFT。SFT 训练收敛之后,就得到了图片中的 checkpoint #1。这个模型经过冷启动数据的微调,不仅拥有了不错的推理能力(R1 的技术报告中称它的性能比 R1-Zero 更好),而且产生的推理过程和结果更友好易读。
第二步:Reasoning-oriented RL
接下来是继续加强他的推理能力,这一个过程使用了和训练 R1-Zero 模型一样的纯强化学习的方法。为了解决语言混杂的问题,这个阶段的 RL 学习过程中加入了语言一致性奖励。这一奖励虽然会损失一些正确率,但是却可以带来更好的可读性。训练完之后得到 checkpoint #2。
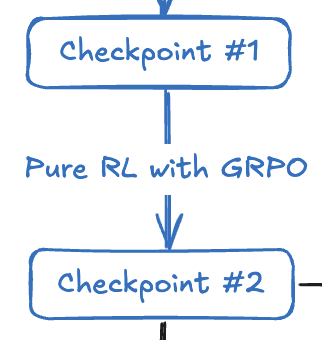
一个有意思的点是,和 R1-Zero 的作用类似,checkpoint #2 对训练 R1 模型的所提供的帮助,是用来生成 R1 训练所需的推理数据,而并不会作为 R1 的基础模型继续优化。
3. 训练最终版 R1
最后一次 SFT 训练
再来一次,用更丰富的数据,从 0 开始微调 DeepSeek-V3-Base,这一次也是最后一次,将使用大约 800K 的精心挑选的训练数据,其中包含 600K 推理数据和 200K 非推理数据,具体如下:
- 推理数据:将经过精心设计的 prompt 输入给 checkpoint #2 模型,从模型的输出中,采用 rule-based 和 DeepSeek-V3 模型评价两种方式来筛选出回答正确的样本,同时再去除掉可读性不高的样本;
- 非推理数据:继续沿用部分 DeepSeek-V3 SFT 过程中所使用的数据。
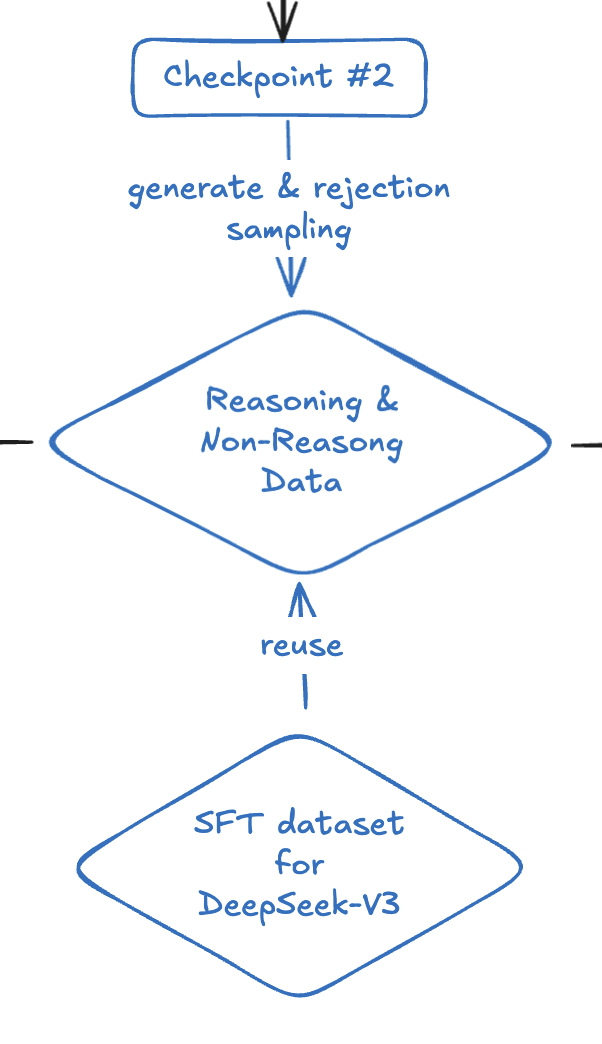
DeepSeek-V3-Base 在这份数据集的基础上微调了 2 轮,得到 checkpoint #3(注意,#3 模型并不是#2 模型的下一个版本)。
很显然 checkpoint #3 在推理任务和非推理任务上都有了更好的表现。接下来进入最后一个阶段的强化学习。
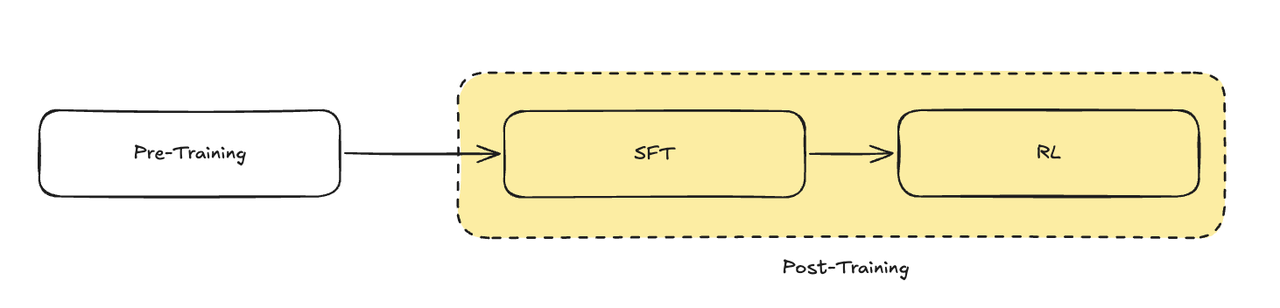
在进入这个阶段之前,让我们再重新来回顾一下标准的大语言模型训练方式,Pre-Traing->SFT->RL,我们会发现 R1 就是严格按照这种方式进行训练的,前面很多步骤看着很繁琐,其实他们只是在生成 R1 训练所需要的数据,并没有修改这种训练方式。
最后的强化学习
这个阶段的目的是进一步增强模型的推理能力,减少模型的危害性,使模型更有帮助。如果你熟悉 RLHF 的话,这个阶段就是在 RLHF 的基础上,再加上推理任务相关的奖励函数,比如针对代码和数学任务的基于规则的奖励函数。
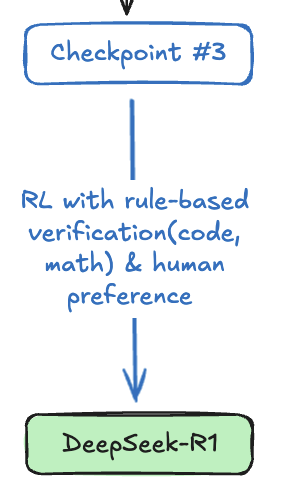
整个过程结束之后,R1 模型就诞生了。
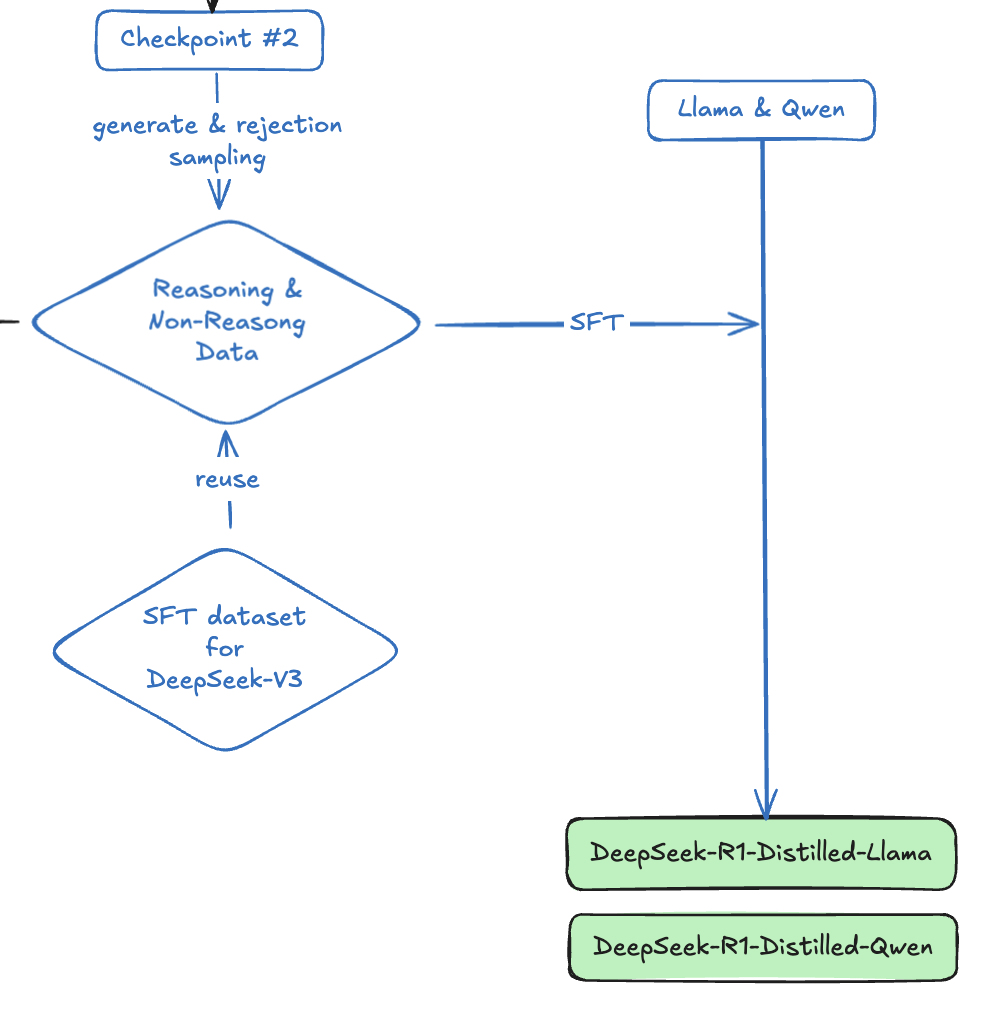
蒸馏小模型
为了验证蒸馏技术的能力,DeepSeek 团队使用 800K 的数据微调了 Llama 和 Qwen 的小尺寸模型,使其具备了更强的推理能力。
三、总结
通过结构化的输出约束、渐进式数据优化与多阶段训练策略,大模型实现了从“直接回答”到“先思考再回答”的质变。
从流程上来看,R1 的训练架构是一个清晰的多阶段优化过程。但技术实现看似清晰的流程背后,实则是海量实验与工程优化的积累。
现在也有论文 Reasoning Models Can Be Effective Without Thinking 提出,在很多任务上,没有显式的思考过程对比显式思考过程,前者会比后者的性能更好。但目前主流的认知依然是,显式思考过程对LLM在处理复杂推理问题时有重大的提升作用。